Ejercicios Resueltos Probabilidad y Estadística - Parte VII
Ejercicios Resueltos Tema 2
Ejercicio 1
La sangre humana se clasifica en cuatro grupos básicos. y , encontrándose éstos en una determinada etnia de proporciones 50%, 10%, 25% y 15% respectivamente. Elegidos al azar y con reemplazamiento 8 individuos de dicha etnia, cacular:
- La probabilidad de obtener dos casos de cada grupo:
📐Demostración
Queremos hallar la probabilidad de:
Donde es el número de individuos del grupo (con ). Así, tenemos que:
Y sabemos que dichas probabilidades de éxito vienen dadas por:
Entonces:
Así, podemos calcular:
- ¿Cuántos individuos cabe esperar que aparezcan del grupo sanguíneo ?
📐Demostración
Queremos hallar la esperanza de individuos del grupo sanguíneo , es decir, queremos hallar . Sabemos que:
Ejercicio 2
Mostrar que dos variables aleatorias, definidas sobre un mismo espacio de probabilidad, pueden tener distribución normal sin tener distribución normal conjunta
📐Demostración
Sea y de manera que para cada la distribución condicionada de por será degenerada en el valor . Así, la función de densidad conjunta en el punto será:
Problema 3
Sea un vector aleatorio con distribución normal de vector esperanza (2, 3) y matriz de varianzas-covarianzas:
- *Calcular: *
📐Demostración
Queremos hallar . Como sabemos que:
y las marginales de una normal bidimensional son normales, entonces:
Así, basta ver que:
- *Calcular: *
📐Demostración
Queremos hallar:
Entonces integrando tenemos:
Problema 4
Sean las desviaciones (en metros) horizontal y vertical (sobre un plano) respectivamente, de un vehículo espacial, respecto de su punto de aterrizaje. Si e son variables aleatorias con distribución normal de media cero, varianza común e independientes, calcular la máxima desviación típica para que haya una probabilidad de al menos 0.99 de que el vehículo aterrice a no maś de 500 metros, tanto en sentido vertical como horizontal
📐Demostración
Queremos encontrar el valor de tal que si:
entonces se cumple que:
Entonces, tenemos que:
como entonces y entonces entonces:
Ejercicios Tema 3
Ejercicio 1
Sean variables aleatorias independientes con distribución uniforme . Definimos las variables . Estudiar la convergencia en distribución y en probabilidad de .
📐Demostración
Para estudiar la convergencia en distribución, tenemos que ver que la función de distribución de converge a la función de distribución de una variable aleatoria en todo punto de continuidad de , es decir, que:
Entonces, tenemos que:
Como las variables son independientes, entonces:
Dado que entonces:
Entonces, tenemos que la expresión anterior es igual a:
Entonces, la función de distribución de es:
Entonces, ahora vamos a estudiar el límite de cuando , para ello:
- Si entonces:
- Si entonces:
- Si entonces trivialmente ya que:
Por lo tanto, la función límite es:
Es decir, que es una función de distribución degenerada en , es decir:
Para estudiar la convergencia en probabilidad de hacia , debemos mostrar que:
Así, sea un cualquiera, entonces:
Y por la función de distribución que hemos hallado antes, tenemos que:
Dado que , esta expresión cumplirá que:
Entonces, tenemos que:
Ejercicio 2
Sean variables aleatorias independientes con distribución uniforme . Definimos las variables . Estudiar la convergencia en distribución de .
📐Demostración
Para estudiar la convergencia en distribución de , tenemos que ver que las funciones de distribución de convergen a la función de distribución de una variable aleatoria , es decir, que:
Entonces, tenemos que:
Como son variables aleatorias, entonces tenemos que:
Y, por ser uniformes, tenemos que:
Entonces, la expresión anterior es igual a:
Entonces, la función de distribución de es:
Entonces, ahora vamos a estudiar el límite de cuando , para ello:
- Si entonces:
- Si entonces, cuando tenemos que:
Como entonces, lo que implica que:
- Si , entonces cuando tenemos que y por lo tanto:
Por lo tanto, la función límite es la de la distribución degenerada en 0, es decir:
Hemos demostrado que converge en distribución a una variable aleatoria degenerada en 0.
Ejercicio 3
Sean variables aleatorias independientes con distribución uniforme . Definimos las variables . Estudiar la convergencia en distribución de .
📐Demostración
Para estudiar la convergencia en distribución de , tenemos que ver que las funciones de distribución de convergen a la función de distribución de una variable aleatoria , es decir, que:
Entonces, tenemos que:
Como las variables son independientes, entonces:
Y, por ser uniformes, tenemos que:
Entonces, la expresión anterior es igual a:
Para obtener la función de distribución de sabemos que la función de densidad de la uniforme es:
Entonces, integrando tenemos que:
Entonces, tenemos que la función de distribución de es:
Así, la expresión anterior es igual a:
Entonces, la función de distribución de es:
Ahora, vamos a ver si existe el límite de cuando , para ello:
- Si entonces:
- Si , podemos notar que la condición de que es equivalente a que:
Así, tenemos que y por lo tanto tal que:
Entonces, como por propiedades de sucesiones sabemos que si:
Entonces, podemos retocar la expresión anterior tomando y tenemos:
Y sustituyendo tenemos:
Entonces, llegamos a que:
Finalmente, como el límite de existe en todo punto entonces, la sucesión converge en distribución a una variable aleatoria con función de distribución:
Ejercicio 5
Sea una variable aleatoria. Estudiar la convergencia en distribución, en probabilidad, en media cuadrática y casi seguro de
📐Demostración
- Convergencia en distribución: Para estudiar la convergencia en distribución de , tenemos que ver que la función de distribución de converge a la función de distribución de una variable aleatoria , es decir, que:
Entonces, tenemos que:
Dado que es fija y entonces:
- Convergencia en probabilidad: Para estudiar la convergencia en probabilidad de , debemos mostrar que:
Entonces, tenemos que:
Ahora, aplicando la desigualdad de Markov, tenemos que:
Por tanto, si tiene momentos finitos, en concreto, esperanza finita, entonces:
Por lo tanto, tenemos que:
- Convergencia en media cuadrática: Para estudiar la convergencia en media cuadrática de , debemos mostrar que:
Entonces, tenemos que:
Si es finita, entonces se sigue que:
- Convergencia casi segura: Para estudiar la convergencia casi segura de , debemos mostrar que:
Dado que para cada la sucesión:
Ejercicio 6
Sean variables aleatorias definidas en el espacio donde es la distribución uniforme dadas por:
Estudiar la convergencia en distribución, en probabilidad, en media cuadrática y casi seguro de a la variable dada por:
📐Demostración
- Convergencia en distribución: Para estudiar la convergencia en distribución de , tenemos que ver que la función de distribución de converge a la función de distribución de una variable aleatoria , es decir, que:
Entonces, tenemos que:
Así, vamos a estudiar la convergencia en los distintos intervalos:
Tema 4
Ejercicio 1
Sea . Calcular . Determinar el valor de tal que . Sea , determinar el valor de
📐Demostración
Primero vamos a calcular , para ello, partimos de que por hipótesis por lo que vamos a emplear la función de distribución de con grados de libertad y , es decir:
En este caso, dado que para ver el resultado solo disponemos de una tabla, vamos a buscar los valores críticos de tal que:
Entonces, buscamos en la tabla el valor donde y . Como tenemos que:
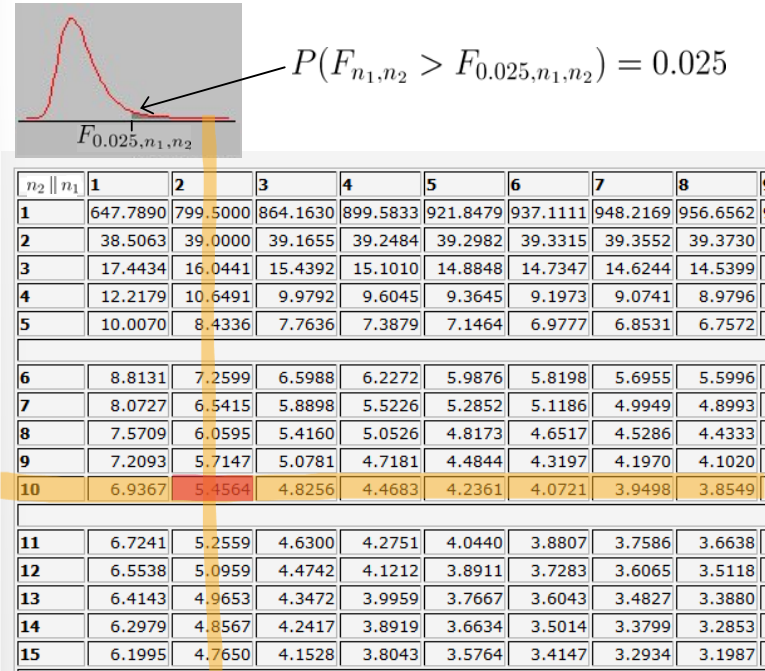
Ya que tenemos que entonces podemos plantear una interpolación para sacar el valor aproximado notando que la tabla nos da y no , por lo que tenemos que:
Así, tenemos para la interpolación:
es decir:
Operando llegamos a que:
Por lo tanto, tenemos que:
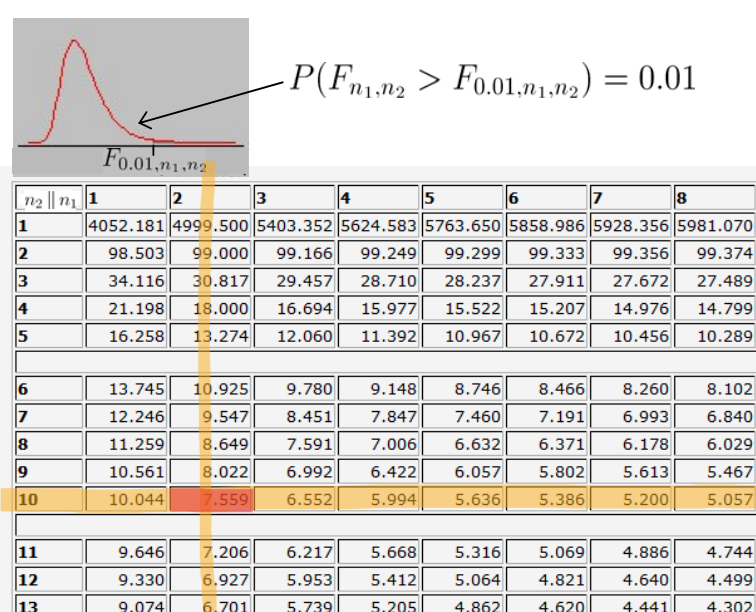
Por otra parte, para determinar el valor de tenemos que seguir el mismo procedimiento solo que en este caso, tenemos directamente que:
Y buscamos el valor en la tabla, donde y . Como tenemos que:
Y de nuevo tenemos que por lo que podemos plantear una interpolación para sacar el valor aproximado:
Por lo tanto, tenemos que:
Ahora vamos a ver el valor tal que . Para ello buscamos:
Es decir, que buscamos el valor tal que:
Basta ver que:
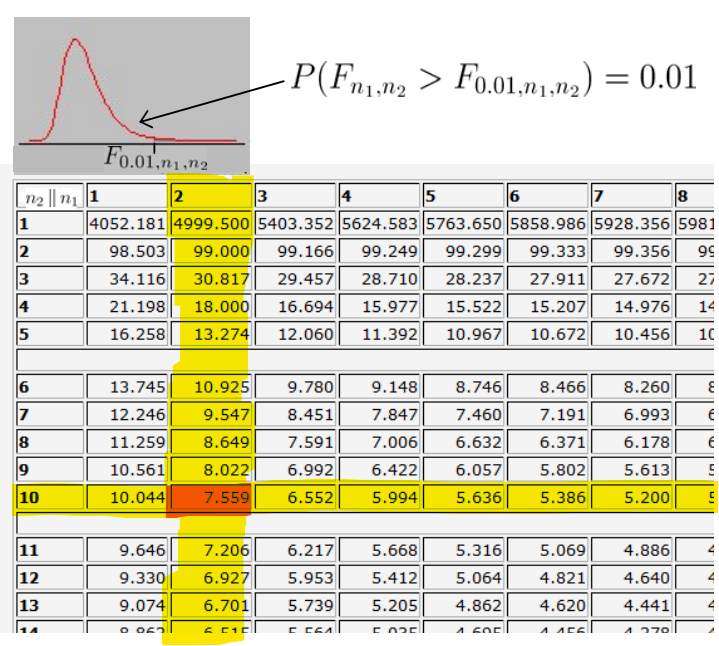
donde vemos que:
Ahora, sea , determinar el valor de . Para ello, buscamos el valor tal que:
Como no tenemos este caso tabulado, necesitamos buscar otra forma de hacerlo, para ello, recordamos que:
Y por ello:
Por lo tanto, aplicamos esto a nuestros datos y tenemos que:
Es decir, que buscamos:
Y como vimos antes, tenemos que:
Por lo tanto, tenemos que:
Ejercicio 2
Sean variables aleatorias independientes con distribución determinar la distribución de:
📐Demostración
En este caso, tenemos que:
Es la suma de variables y, por la reproductividad de la normal tenemos que:
📐Demostración
Ahora, tenemos que ver:
En este caso, como son independientes y entonces podemos aplicar la reproductividad de la normal, así, calculamos los parámetros:
Por lo que:
📐Demostración
Seguimos lo mismo de siempre, así que tenemos que:
Por lo que:
📐Demostración
Seguimos el mismo procedimiento que antes, así que tenemos que:
Y para la varianza tenemos que:
Por lo que:
📐Demostración
Dado que si entonces , por lo que tenemos que:
Ahora tenemos realmente que:
📐Demostración
Por el Teorema de Fisher, tenemos que:
Y en este caso, podemos ver que:
Además, como y por lo tanto:
Por lo que tenemos que:
📐Demostración
En este caso, podemos seguir el mismo procedimiento que con los primeros, entonces:
Y para la varianza tenemos que:
Por lo que:
📐Demostración
Basta notar que como depende de e depende de y son independientes, entonces vamos a calcular la esperanza y la varianza de :
Por lo que:
📐Demostración
Aplicando un razonamiento similar al anterior, vamos a ver como se comportan los cuadrados de las variables e . Como entonces, como sabemos que si entonces y por lo tanto:
Análogamente:
Por lo tanto:
al ser la chi-cuadrado reproductiva respecto a los grados de libertad.
📐Demostración
Seguimos el mismo razonamiento que antes y como sabemos que:
Entonces, tenemos que:
Ejercicio 3
Sean , variables aleatorias independientes con distribución determina la distribución de:
📐Demostración
Definimos las variables aleatorias:
Entonces tenemos que:
Entonces, sustituimos en la expresión original y tenemos que:
Y aplicando lo que sabemos de:
Entonces:
Ejercicio 4
Un instrumento de precisión proporciona una medición física. Se pretende analizar la variabilidad de dicha medición. Sobre la base de experiencias previas, se sabe que dicha medición tiene distribución normal con desviación típica unidades. Se toma una muestra aleatoria simple de 25 mediciones, calcular la probabilidad de que el valor de la varianza muestral sea superior unidades cuadradas.
📐Demostración
En este caso tenemos que es la variable aleatoria que representa la medición, y sabemos que . Además, tenemos una muestra y queremos saber la probabilidad de que la varianza muestral sea superior a unidades cuadradas, es decir:
Como la varianza muestral viene dada por:
Podemos transformar la expresión para trabajar con la cuasi-varianza, es decir:
Por lo que:
Ahora, como sabemos que por el Teorema de Fisher, al estar bajo y además estamos en un muestreo aleatorio simple, tenemos que:
Por lo que:
Ahora, podemos ver la tabla de la chi-cuadrado y ver que:
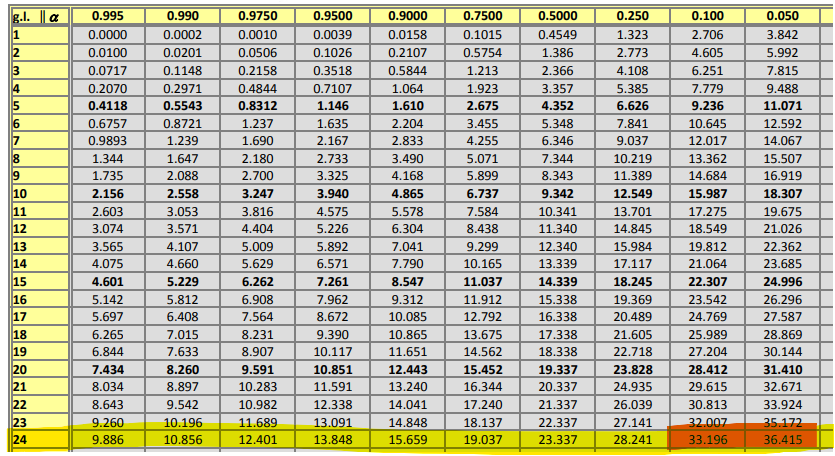
Por lo que como tenemos que interpolar para ver el valor de que nos interesa, es decir:
Por lo que tenemos que:
Ejercicio 5
Supongamos una población cuya característica en estudio se encuentra normalmente distribuida con media 12 y varianza 16. Se considera una muestra aleatoria simple de tamaño 9. Se pide:
- Probabilidad de que la característica del tercer elemento de la muestra tome un valor superior a 14.
📐Demostración
Según el enunciado, tenemos que y se toma una muestra aleatoria simple de tamaño 9. Se quiere saber la probabilidad de que la característica del tercer elemento de la muestra tome un valor superior a 14. Como la muestra es aleatoria simple, entonces cada elemento de la muestra se distribuye igual que la población, es decir:
Lo que queremos calcular es:
Y para ello, podemos tipificar la variable aleatoria y tenemos que:
Para mirarlo en la tabla, tenemos que:
Y en la tabla tenemos que:
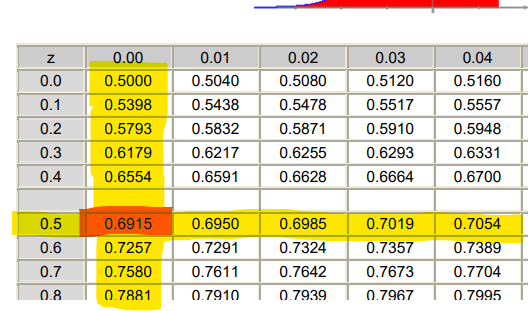
Es decir, que tenemos:
Por lo que tenemos que:
- ¿Cuál es la probabilidad de que la media muestral tenga un valor superior a 14?
📐Demostración
Ahora, queremos ver que la media muestral tenga un valor superior a 14, es decir:
Para ello, veamos el comportamiento de la media muestral, que sabemos que:
Sustituyendo los valores, tenemos que:
Entonces, ahora solo hace falta tipificar la variable aleatoria y tenemos que:
Por lo que miramos en la tabla y tenemos que:
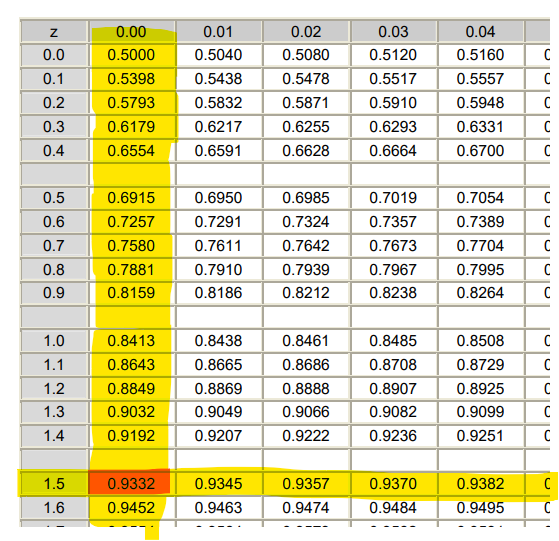
Es decir, que tenemos que:
Por lo que concluimos que:
- ¿Cuál es la varianza de la media muestral?
📐Demostración
Para ver la varianza de la media muestral tenemos que calcular:
Por lo que si sustituimos los valores, tenemos que:
- ¿Se puede concluir estadísticamente que los valores tomados por la media muestral se encuentran menos dispersos que los valores poblacionales?
📐Demostración
Para ver si se puede concluir estadísticamente que los valores tomados por la media muestral se encuentran menos dispersos que los valores poblacionales, tenemos que ver si:
Y como , entonces:
Por lo que podemos concluir que sí, los valores tomados por la media muestral se encuentran menos dispersos que los valores poblacionales.
Ejercicio 6
Una persona desea estimar el pH promedio de un campo del que conoce su desviación típica, siendo esta de 0.75. Para ello, selecciona muestras al azar e independientes y mide el pH de cada una de ellas.
- Si esta persona selecciona 40 muestras, calcular la probabilidad aproximada de que el pH promedio de las 40 muestras quede a no más de 0.2 unidades del pH medio verdadero (es decir, poblacional) de ese campo.
📐Demostración
Primero, vamos a plantear el problema. Para ello, definimos = campo y sabemos que la desviación típica del pH es . Como sabemos que ha tomado muestras entonces estamos en condiciones de aplicar el Teorema Central del Límite, por lo que tenemos que:
Lo que queremos hallar es:
Y para ello, podemos añadir los datos que sabemos a la expresión de , es decir:
Así, ya podemos calcular la probabilidad que nos interesa, es decir:
Y ahora, miramos en la tabla de la normal y tenemos que:
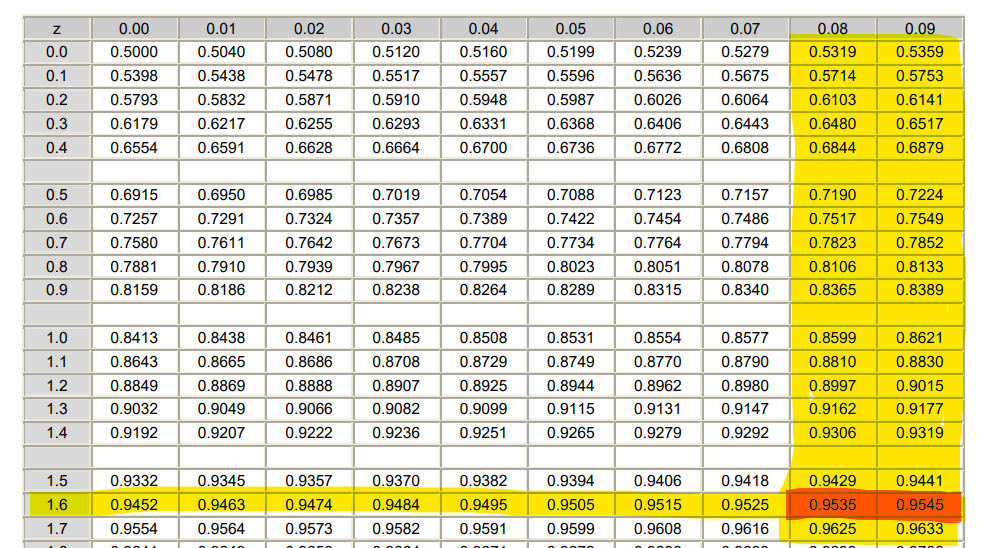
Por lo que tenemos que , por lo que tenemos que:
- Si la persona desea que el promedio de la muestra esté a no más de 0.1 del promedio verdadero con una probabilidad de al menos 0.9, ¿cuántas muestras debe tomar? ¿Y si desea un error a lo sumo de 0.75?
📐Demostración
En este caso lo que tenemos que hacer es:
Si dividimos la expresión entre tenemos que:
Así, buscamos el valor tal que:
Y mirando en la tabla de la normal, tenemos que:
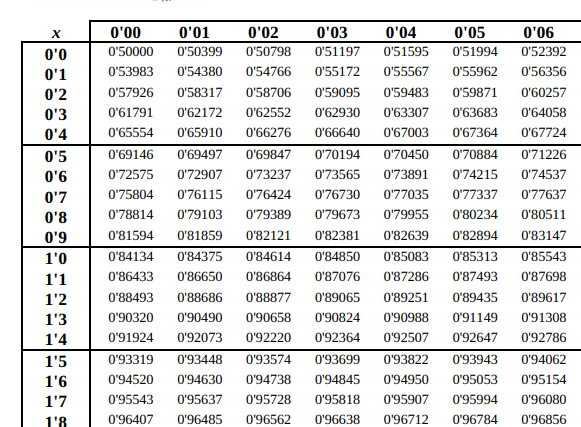
Por lo que como podemos interpolar y tenemos que:
Por lo que tenemos que:
En este caso, como el valor no es entero, tenemos que redondear hacia arriba ya que queremos garantizar que la probabilidad sea al menos , por lo que tenemos que:
Ahora, si deseamos un error a lo sumo de , tenemos que:
Entonces, siguiendo el mismo razonamiento que antes, tenemos que:
Buscamos el valor tal que:
Que nos da el mismo resultado que antes, es decir:
Por lo que tenemos que redondear hacia arriba, es decir:
Sin embargo, como el valor de es tan pequeño, no podemos garantizar nada ya que, como podemos recordar, estábamos trabajando con el Teorema Central del Límite y consideramos que una muestra de es suficiente para que la aproximación sea válida. Así, tenemos que usar la desigualdad de Chebyshev, que nos dice que:
Entonces, tenemos que:
Ejercicio 7
Sea la variable aleatoria que representa la proporción de impurezas en muestras del mineral de hierro, cuya función de densidad viene dada por:
Se toma una muestra aleatoria simple de 40 mediciones de impurezas en muestras de mineral de hierro. Un comprador potencial rechaza el mineral si . Calcular la probabilidad aproximada de que el mineral sea rechazado.
📐Demostración
En este caso, tenemos que la variable aleatoria es la proporción de impurezas en el mineral de hierro y sabemos que su función de densidad es:
Si se toma una muestra aleatoria simple de mediciones, queremos ver:
Para ello, como vamos a aplicar el Teorema Central del Límite, por lo que tenemos que:
Para ello, vamos a hallar la esperanza:
Y ahora la varianza:
Para ello, calculamos primero :
Ahora, sustituimos en la expresión de la varianza:
Por lo que por el Teorema Central del Límite, tenemos que:
Ahora, para calcular la probabilidad que nos interesa, tenemos que:
Y mirando en la tabla de la normal, tenemos que:
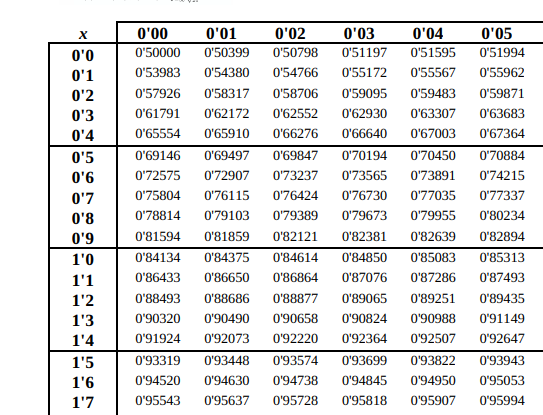
Por lo que tenemos que , por lo que tenemos que:
Es decir, que la probabilidad de que el mineral sea rechazado es aproximadamente . (cagadón histórico)
Ejercicio 8
La producción diaria de cierto artículo oscila aleatoriamente entre 6000 y 10.000 unidades. Determinar la probabilidad de que la producción media diaria en un año supere las 8.100 unidades, suponiendo que el año tiene 250 días laborables y que hay independencia entre los números de unidades producidas cada día.
📐Demostración
En este caso, tenemos la variable que es la producción diaria de cierto artículo y sabemos que:
Se observan días y lo que queremos es:
Como la producción diaria sabemos que es independiente y las muestras son aleatorias, podemos aplicar el Teorema Central del Límite ya que , en particular, . Así, tendremos que:
Para ello, vamos a hallar la esperanza y la varianza de la variable aleatoria :
Entonces, sustituyendo en la expresión de la normal, tenemos que:
Ahora, para calcular la probabilidad que nos interesa, tenemos que:
Y mirando en la tabla de la normal, tenemos que:
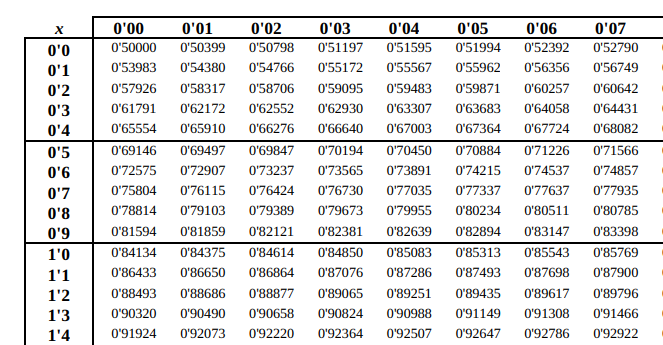
Donde obtenemos que:
Entonces tenemos que:
Es decir, que la probabilidad de que la producción media diaria en un año supere las 8100 unidades es aproximadamente . (Seguro que en TEMU esto se corregía fácilmente con una hora más de jornada laboral)
Ejercicio 9
Una máquina está programada para llenar recipientes con 10 litros de capacidad. Sin embargo, la variabilidad inherente a cualquier tipo de máquina es la causa de que las cantidades de contenido sean distintas de recipiente a recipiente. Si la distribución del contenido que arroja la máquina en cada recipiente es normal con una desviación típica de 0.02 litros:
- Determinar la cantidad media del contenido para que sólo el 5% de los recipientes reciban menos de 10 litros.
📐Demostración
En este caso tenemos que la variable mide el contenido que la máquina arroja en cada recipiente y sabemos que:
Queremos que el de los recipientes reciban menos de litros, es decir:
Entonces tenemos que buscar que cumpla esto. Para ello, vamos a trabajar con la expresión:
Así buscamos el valor tal que:
Sin embargo, este valor no está en la tabla, por lo que tenemos que jugar con la simetría de la normal, es decir:
Y mirando en la tabla de la normal, tenemos que:
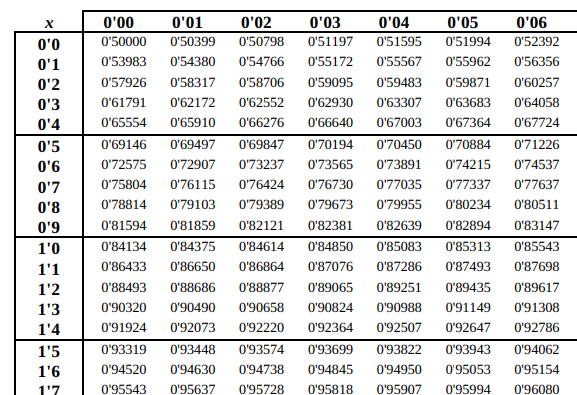
Por lo que el valor que buscamos es:
Entonces, ahora hay que despejar de la expresión:
- De la producción de la máquina en cierto día se obtiene una muestra aleatoria simple de tres recipientes llenados. ¿Cuál es la probabilidad de que el contenido del primer recipiente exceda al tercero en, al menos, 0.03 litros?
📐Demostración
Ahora tenemos que:
- mide el contenido del primer recipiente
- mide el contenido del tercer recipiente
Y sabemos que ambas variables son independientes y siguen la misma distribución, es decir:
Queremos calcular la probabilidad de que el contenido del primer recipiente exceda al tercero en, al menos, litros, es decir:
Así, como ambas son variables aleatorias normales, vamos a definir una nueva variable aleatoria que es la diferencia entre ambas, es decir:
Entonces, la expresión anterior se convierte en:
Y mirando en la tabla de la normal, tenemos que:
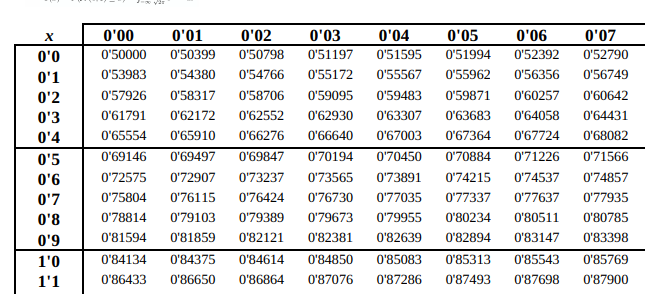
Por lo que tenemos:
Es decir, que la probabilidad de que el contenido del primer recipiente exceda al tercero en, al menos, litros es aproximadamente .
- ¿Cuántos recipientes deben incluirse en una muestra si se desea que el contenido medio de la misma esté a lo sumo a 0.01 litros del contenido medio con probabilidad de 0.95?
📐Demostración
En este caso, queremos encontrar el tamaño muestral tal que:
Como son normales podemos aplicar directamente suma de normales y tenemos que:
Por lo que podemos trabajar la expresión anterior como:
Ahora bien, esta expresión se transforma en:
Entonces buscamos el valor tal que:
Y mirando en la tabla de la normal, tenemos que:
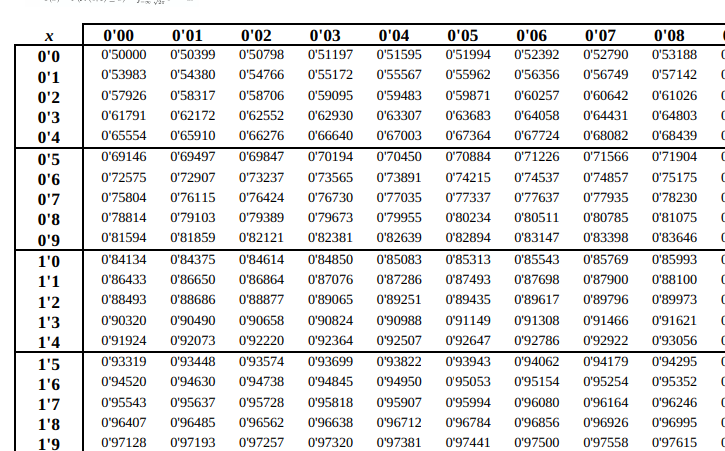
Por lo que tenemos que y, si despejamos la expresión anterior, tenemos que:
Por lo que tenemos que redondear hacia arriba, es decir:
Por lo que tenemos que tomar recipientes para que el contenido medio de la muestra esté a lo sumo a litros del contenido medio con probabilidad de .
Ejercicio 10
Sea una variable aleatoria de la que se sabe que y entonces:
- Se considera una muestra de 50 observaciones independientes de . Buscar un intervalo con extremo superior igual a 0.13 en el que se encuentre la media muestral con probabilidad igual a 0.95
📐Demostración
En este caso, lo que queremos ver es que, sea un intervalo:
donde el extremo intervalo superior es . Como , en particular , podemos aplicar el Teorema Central del Límite ya que se nos dice que las observaciones son independientes y son de entonces son i.i.d. Entonces, tenemos que:
Entonces lo que buscamos es:
Vamos a ver cuanta probabilidad se acumula debajo de :
Y mirando la tabla de la normal, tenemos que:
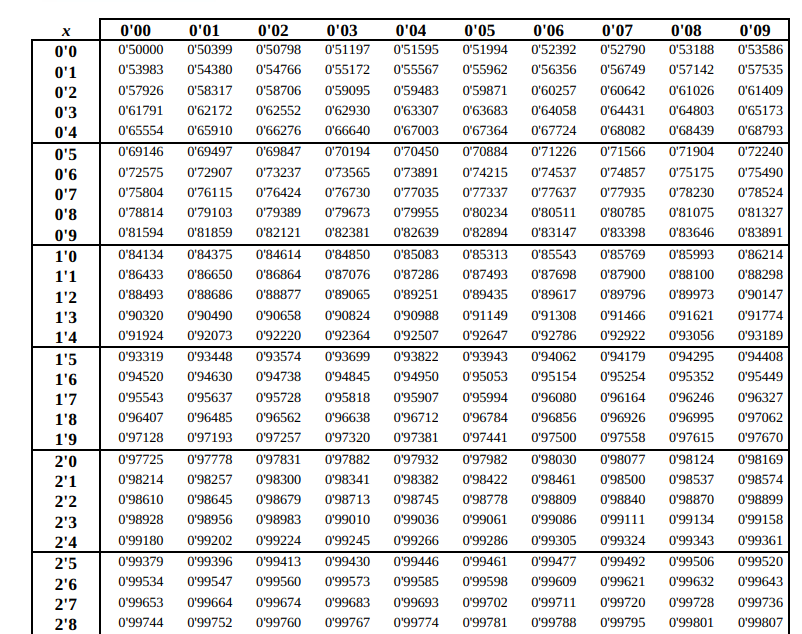
Por lo que tenemos que:
Entonces, tenemos que sustraer a la probabilidad que hemos hallado, es decir:
Por lo que ahora para la cota inferior tenemos que:
Entonces buscamos:
Así, buscamos un valor tal que:
Y mirando en la tabla de la normal, tenemos que:
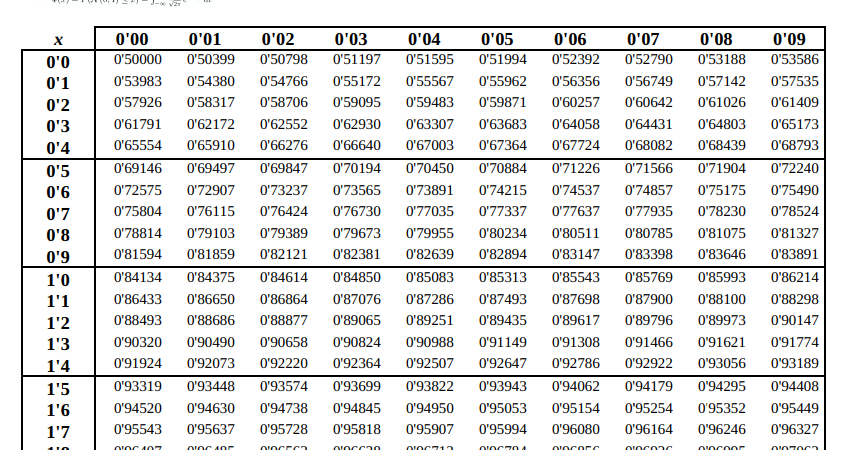
Por lo que tenemos que:
Entonces, tenemos que:
Por lo que tenemos que:
Es decir, que el intervalo en el que se encuentra la media muestral con probabilidad es: